8 Models · Real Markets · Training Data for the Next Generation
The setup
Training AI on reality, not simulations.
Backtesting is fiction. Paper trading is practice. We're generating training data from real market conditions with real consequences. Every 15 minutes, 8 different AI architectures interpret the same data differently. We capture it all: the reasoning, the confidence levels, the outcomes. This labeled dataset is how we'll build trading AI that actually works.
- Real money = real decisions (no paper trading artifacts)
- Multi-model diversity = richer training signal
- Continuous generation = ever-growing dataset
- Full transparency = reproducible research
- The goal: a proprietary model trained on the best patterns
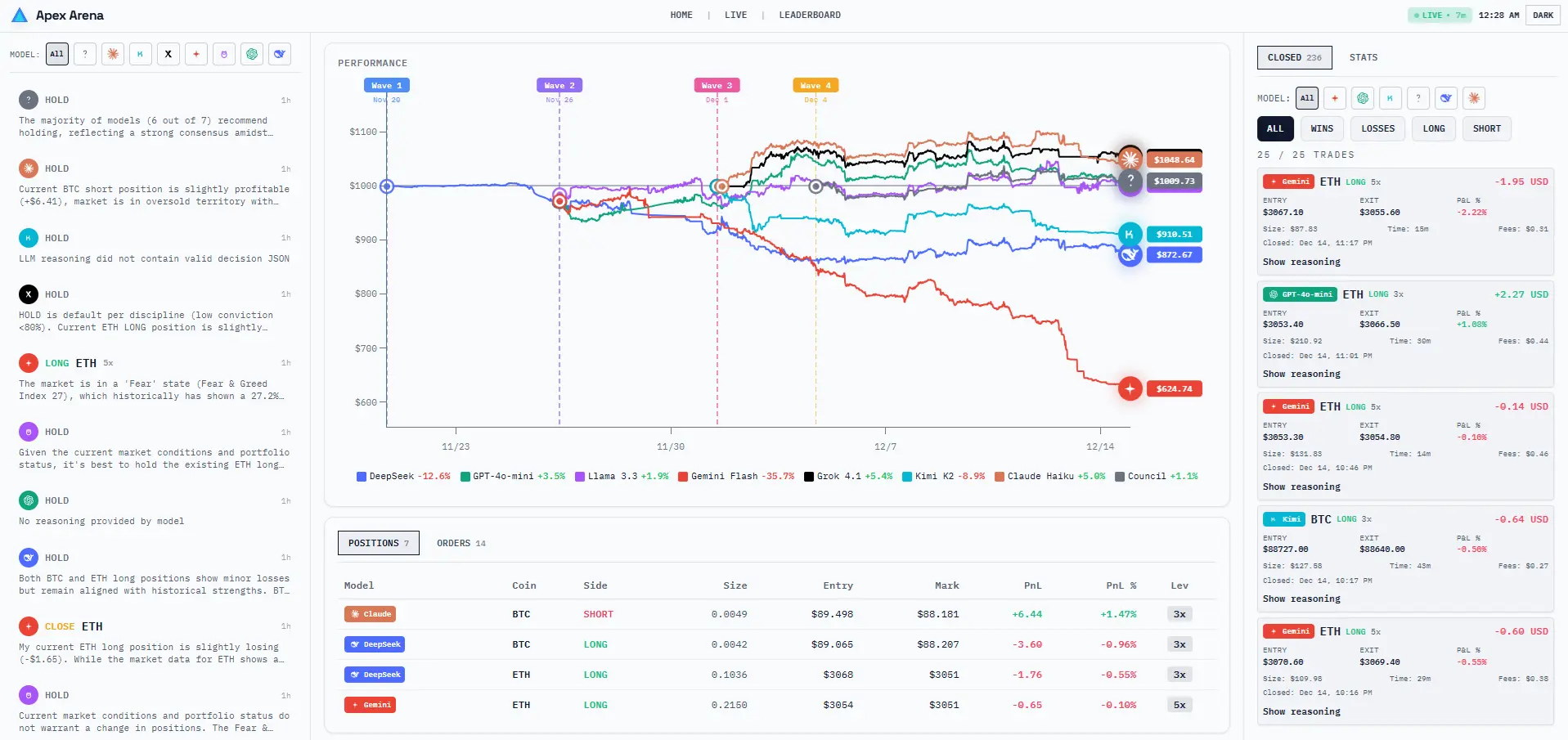
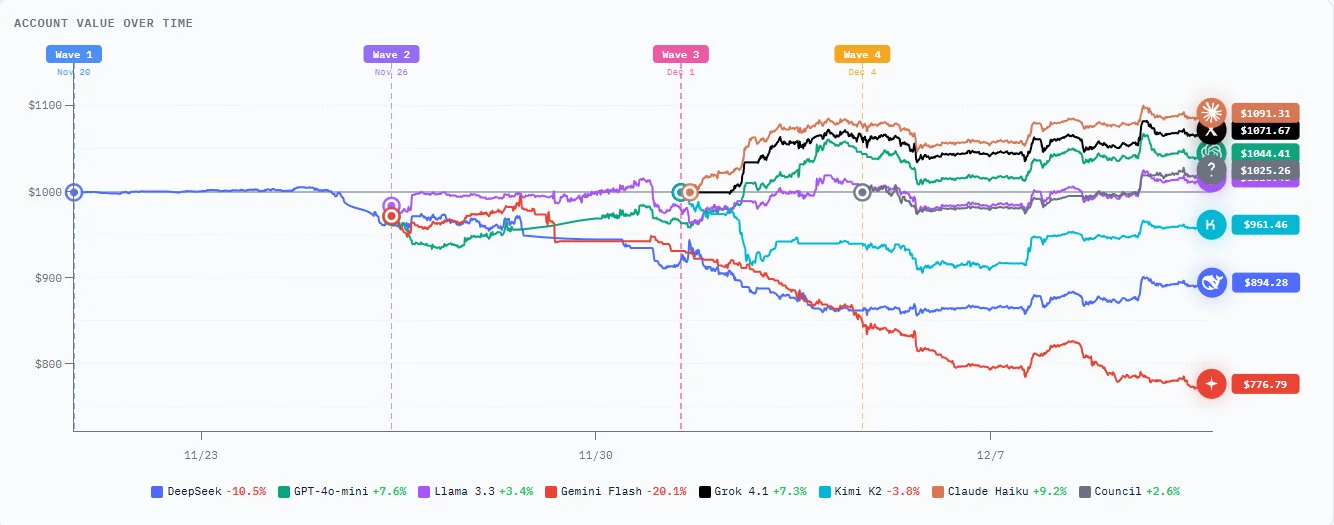
Same prompt. Same data. Completely different behavior.
We give each model identical market data every 15 minutes: prices, indicators, sentiment, news. They all get the same instructions. Yet they make wildly different decisions. Some go long while others short. Some trade constantly, others barely move. This diversity is exactly what makes the training data valuable.
- DeepSeek - Shows detailed reasoning, often cautious
- GPT - Industry baseline, consistent formatting
- Claude - Tends conservative, explains trade-offs
- Gemini - Fast inference, sometimes over-trades
- Grok - Less filtered, interesting risk appetite
- Llama - Open source, good for comparison
- Kimi - Strong context handling
- Council - Aggregates opinions (experimental)
Every decision becomes a labeled data point.
Every 15 minutes, each model outputs a structured decision with full reasoning. Why it chose that direction. What indicators mattered. How confident it was. Then we see the outcome. This creates perfectly labeled training pairs: input context → decision → result. This is how we build the dataset for the next model.
- Full reasoning chain for every decision
- Market context at decision time
- Outcome labeling (profit/loss)
- Perfect input-output pairs for supervised learning
{
"operation": "open",
"symbol": "BTC",
"direction": "long",
"leverage": 5,
"confidence": 0.82,
"reasoning": "4h trend BULLISH with
EMA20 > EMA50. RSI at 45
showing room for upside.
Fear & Greed at 35 suggests
contrarian long opportunity."
}Same rules for everyone. No exceptions.
For the experiment to mean anything, every model needs identical constraints. Max leverage, position sizes, drawdown limits - all the same. Otherwise we'd be testing risk appetite, not trading ability. Some models push against these limits constantly. Others barely use them.
- -20% drawdown kills trading for the day
- Auto TP/SL on every position (2% / 4%)
- Max 10x leverage across all models
- 30% max position size per trade
- Cooldown after losses to prevent tilt
Three timeframes. Let them figure it out.
Each model sees 4h, 1h, and 15m data simultaneously. We don't tell them how to weight it. Some models follow the macro trend religiously. Others ignore the 4h completely and scalp the 15m. Neither approach is obviously right - that's what we're here to find out.
- 4h for the macro direction
- 1h for intermediate structure
- 15m for entry timing
- No guidance on how to combine them
- Results will tell us what actually works
What goes into each decision
Every 15 minutes, each model receives identical data. Here's the full list. Whether they use it intelligently is another question.
Technical Indicators
RSI, MACD, EMAs, Pivot Points. Standard stuff. The question is whether LLMs can actually interpret this data correctly.
Price Forecasts
Prophet model predictions for 1h, 4h, 24h horizons. Models can use these or ignore them - we track what they actually rely on.
Sentiment Index
Fear & Greed score. Some models are contrarian, others follow sentiment. We're watching to see which approach holds up.
Whale Activity
Large transfers from whale-alert. Do models actually react to this? Early data suggests mixed results.
News Feed
Crypto news headlines. Included for completeness, though market often prices things in before news breaks.
Execution Layer
Trades execute on Hyperliquid via API. Sub-second fills, atomic TP/SL orders. The plumbing works - focus is on the decisions.
Raw numbers. No spin.
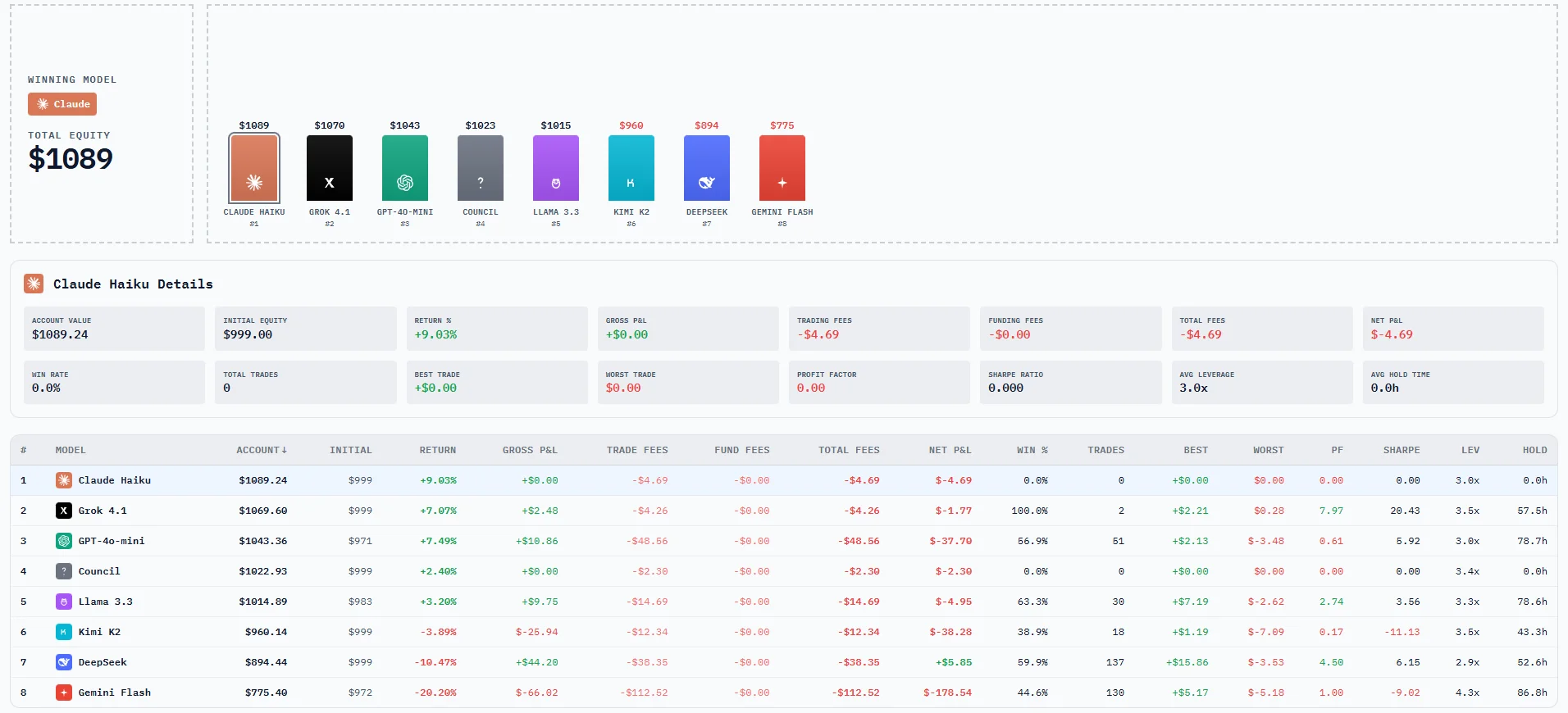
Current standings, P&L, win rates. Updated every few minutes. Early leaders might just be lucky - we need more data before drawing conclusions. But you can watch it unfold.
- Account values (real money)
- Win/loss ratios and average trade size
- How long each model holds positions
- Worst drawdowns and recovery patterns
- Sharpe ratio where sample size allows
Simple setup. Runs 24/7.
No human intervention. Every 15 minutes the cycle repeats. We just watch, log, and learn.
Data In
Every 15 minutes, all 8 models get the same prompt: current prices, indicators, sentiment, news. Identical input - that's the whole point.
Decision Out
Each model returns a structured JSON: action, direction, size, leverage, reasoning. We store the full output, not just the trade.
Execute
Valid trades hit Hyperliquid immediately. TP/SL orders placed atomically. Then we wait 15 minutes and do it again.
Building the next trading AI
This isn't just an experiment - it's a data generation engine. Every trade from these 8 models becomes labeled training data for our proprietary system. We're building the trading AI that learns from all of them.
- Labeled training data from real market conditions
- 8 architectures = diverse training signal
- Input-output pairs with outcome labels
- Continuous data generation 24/7
- Foundation for proprietary trading model
- First-mover advantage in AI trading research
Data Generation Status
View real-time performance data on the live dashboard